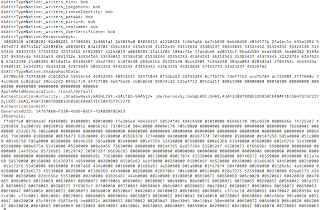
In recent years, phishing has become an increasingly profitable attack vector for online scammers. According to RSA’s The Year in Phishing (2013) report, the total number of phishing attacks in 2012 increased by 59% and resulted in global losses of $USD 1.5 billion. With this upward trend in online fraud predicted to continue, it’s pertinent to take a look at how these attacks are so successful and what can be done to buck the increasing trend of online fraud. Phishing is the process whereby someone (malicious) masquerades as a trusted entity to solicit information. Relying on the art of deception, these attacks fair particularly well online as people are less likely to pick up on the fraud cues. Phishers frequently target email as their preferred attack medium due to its lack of security controls – in particular, the absence of authentication. The critical issue surrounding email is trust. That is, how can we trust an email has come from who it purports to come from? If we look at